Genie in a Network (GIN) is a next-generation network management and analytics platform that is designed to significantly reduce the complexity associated with managing large networks.
- Overview
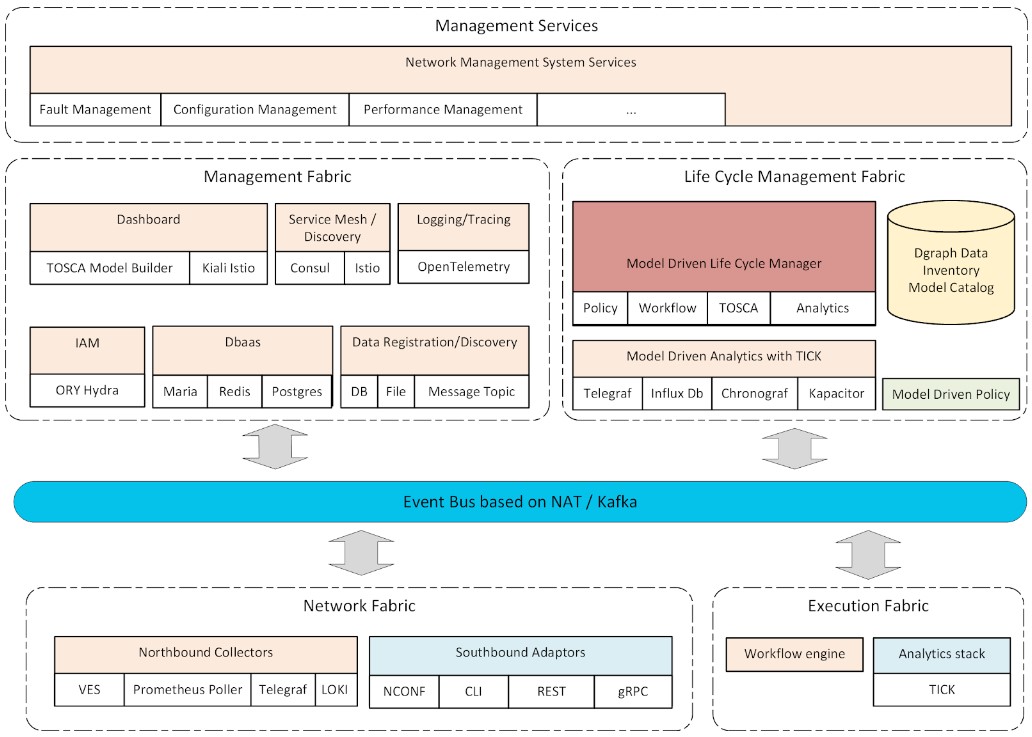
- Architecture
- Life Cycle Management Fabric
- Network Integration Fabric
- Management Integration Fabric
- Execution Fabric
- Quality Assurance & Testing
- Use Cases
- Management Services
- Service Orchestrator
- TOSCA Based Orchestrator
- TOSCA Model Registry
- TOSCA Model Database
- Event Bus
- Workflow Engine
- Policy Engine
- Security
- Service Orchestration Workflow
Overview
Genie in a Network (GIN)™ is a next-generation network management and analytics platform that has been expressly designed to address the shortcomings of legacy network management approaches. Network operators have historically built management systems based on vendor-specific tools, dedicated element management systems, and special-purpose controllers, each of which manages only a small subset of the network. These tools often use incompatible interfaces or data schemas, resulting in integration nightmares. As the number of network elements grows—because the scale of the network increases and virtualization and disaggregation become the norm—so will the number of required management tools. In this environment special-purpose management tools are no longer practical, since the size of the management system will grow in concert with the network, and the challenge of integrating the management components will grow exponentially.
This situation calls for a different management approach that moves away from fixed function dedicated management tools in favor of programmable general-purpose tools. Such tools need to be customizable or programmable at runtime to provide specific network management functionality and to adapt to vendor specific and technology specific devices. The tools must also scale to handle very large volumes of network monitoring and telemetry data and include the necessary capabilities for registering, discovering, describing, storing, and processing such data.
The CCI GIN platform introduces a novel network management paradigm that is designed to significantly reduce the complexity associated with managing large networks. This network management paradigm provides the following benefits:
- GIN unifies—it provides uniform network management around a common model-driven management paradigm. GIN’s unified management approach significantly reduces the number of management system components—fewer moving parts—which results in a more resilient system and avoids the accumulation of technical debt.
- GIN is open and standards-based—it uses the OASIS TOSCA standard for defining service models and associated management operations on those models. Collections of TOSCA definitions—TOSCA profiles—can be created to represent various standards, including 3GPP, O-RAN, Kubernetes, ETSI NFV, etc. The use of an open standard avoids the need for operators, their partners, and their vendors to incorporate proprietary technologies into their solutions.
- GIN simplifies—by using TOSCA’s declarative management paradigm, GIN avoids the complexities typically associated with programmable platforms. A declarative paradigm enables no-code and low-code approaches that create services from packages of pre-defined reusable components. This approach significantly reduces the complexity of service design and enables faster time-to-market for new services as well as the creation of one-off custom services.
- GIN accelerates—not only does GIN simplify new service creation, but it also accelerates the definition of the operational aspects of new services. The GIN platform encourages designers to specify monitoring and service assurance aspects of their services in concert with the service definitions themselves. By defining provisioning and assurance all in one place, service assurance will no longer need to be bolted on as an afterthought. By baking service assurance into service design, operators will be able to accelerate time to market for new services while at the same time improving service reliability.
- GIN scales—it includes comprehensive data management infrastructure that leverages almost a decade of experience with FoxStream—CCI’s solution for handling large volumes of telemetry and analytics data. In addition, GIN introduces new roll-up and drill-down functionality for analytics data that is based on TOSCA’s substitution mapping feature. This functionality provides a structured approach for operators to get a handle on large volumes of monitoring data without losing sight of the underlying detail where necessary.
Architecture
Genie in a Network (GIN)™ is a TOSCA-based service life cycle and FCAPS management platform that addresses the challenges of handling increased need for automation, being cloud native, and dealing with lifecycle management of network functions, management functions, and infrastructure on which it runs. The platform allows you to build a comprehensive model of a service including resources, workflows, policies, and analytics it depends on – all defined in one location.
It adopts a number of core foundational principles to tackle the complexity of modern network deployments:
Declarative – A declarative approach reduces complexity. It focuses on the “what” rather than the “how”. The automation platform translates the declarative to the imperative.
Model-Driven – A model-driven approach provides a consistent set of models used by all platform components. It helps automation by using the meta-model or “modeling language” to define the automation functionality associated with the modeled components.
End-to-End – Service designers and network function designers can design all aspects of lifecycle management in one place. Service and network function deployment packages support all aspects of Day 0 design, Day 1 deployment, and Day 2 lifecycle management, including service assurance.
Comprehensive – End-to-end automation systems must not only handle lifecycles and assurance of services and network functions, but also the infrastructure on which network functions are hosted and the service lifecycle management systems themselves.
Cloud-Native – A cloud-native system helps facilitate a loosely-coupled event-driven architecture over tightly-coupled monolithic systems. It allows us to dynamically scale network management functions and make them easily distributable all the way to the edge.
Open and Extensible – The architecture supports open interfaces to integrate with existing management systems and to support addition of custom management functionality.
These foundational principles allow true automation without adding complexity.
The key features of the platform can be summarized as follows:
- Consistent TOSCA based models for Day 1 orchestration and Day 2 operation, removing the need for subdomain orchestrators like APPC, VNFC, and SDNC.
- Inferred workflows from relationships defined in the service model
- Explicit workflows can also be specified in the TOSCA model. No separate definition required in an external workflow engine.
- Policies can be specified in the TOSCA model. No separate definition required in an external policy framework/engine.
- Monitoring and analytics designed in conjunction with services and service components, and bundled with Service Models.
- Multi-cloud deployment for a model can be declared in the model using the TOSCA substitution mapping feature
- Persistence storage for the model and resources built on TOSCA entities, that requires no changes to the schema for new resources or components.
While GIN is inspired by ONAP, GIN adopts a fundamentally different architecture which allows it to address the many shortcomings of ONAP.
Life Cycle Management Fabric
Genie in a Network (GIN)™ Life Cycle Management Fabric is key to meeting the declarative and model driven core principles of this platform. It consists of the following main features:
A. Model-Driven Lifecycle Manager – replaces the Service Orchestrator as well as the controllers in ONAP with pure TOSCA-based orchestrator. The TOSCA meta-model defines abstractions that are fully aligned with its mission as service orchestration language. It introduces service topologies as first-class abstractions, which are modeled as graphs that contain the components (“nodes”) that make up a service as well as the relationships between these components. Each component can in turn be modeled as a (sub) topology of more fine-grain nodes and relationships. The decomposition is recursive, which allows for fine-grain components. TOSCA types allow for the creation of reusable components, TOSCA requirements allow service designers to express resource requirements directly in their service models to be matched at orchestration time with capabilities of inventory resources and modeled using the same TOSCA meta model. The supported lifecycle management operations are defined on each node using Interfaces and Operations and implemented using Artifacts. TOSCA’s service-focused meta model enables automated general-purpose orchestration capabilities.
The lifecycle management functionality of controllers/sub-domain orchestrators is built around the same service-focused meta model as the master orchestrator. This allows us to turn controllers into domain-specific orchestrators, built using the same orchestration functionality as the master orchestrator, but using domain-specific TOSCA models. The communication between master orchestrator and controllers follows a “decompose and delegate” paradigm. Controllers can further decompose components internally using TOSCA substitution mapping, avoiding the need for monolithic plug-ins. As a result, the “domain level orchestrators” (controllers) in ONAP such as, APPC, VNFC, and SDNC have been eliminated.
Most service lifecycle management workflows have complex dependencies which results in complex sequencing of orchestration steps. The sequencing may be too complicated for humans to get right, orchestration software is better equipped to determine sequencing of orchestration steps based on dependencies represented in service topology. We can bundle service-specific orchestration logic together with service models in a way that can be understood by all orchestrator components. We can also bundle service-specific policies together with service models, all defined using the same TOSCA language.
Since TOSCA specification’s support for workflows and policies is more than adequate for what is needed, we significantly reduce the complexity of the current ONAP implementation which depends on tediously convoluted and full-blown workflow engines like Camunda, and Drools based policy engines to fulfill this requirement.
TOSCA enables us to define all service specifics in one place, that can be understood by the life cycle manager in a service-independent way.
The life cycle manager is implemented using a Golang based microservice and has a REST API for integration with external applications.
B. Model-Driven Analytics – the lifecycle manager uses a common analytics framework consisting of the TICK. One of the key advantages of the lifecycle manager is that the monitoring parameters and associated analytics
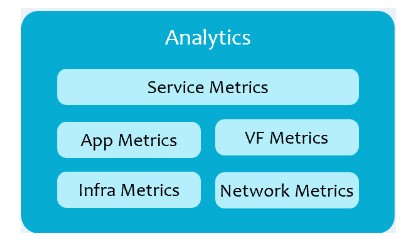
defined by service designers can be bundled with the service models. Analytics will include metrics on services, apps, virtual functions, infrastructure, and the network itself. It can be used to collect and display performance metrics, send alerts, participate in closed loop automation, etc.
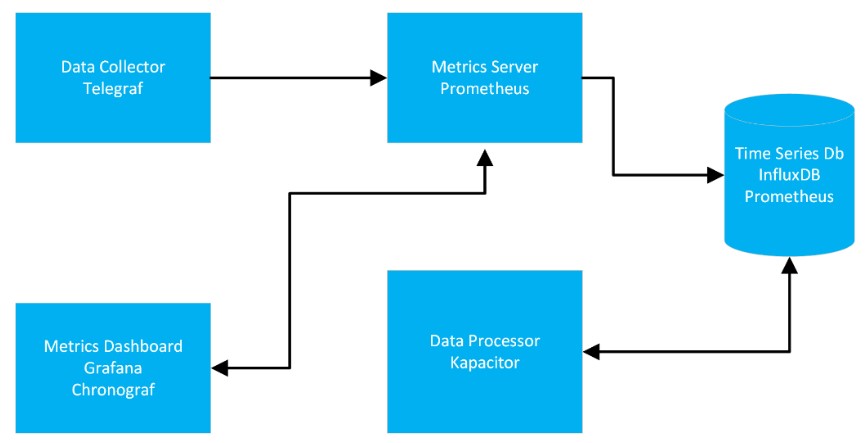
Typically, the analytics stack consists of a data collector that collects metrics from a VNF, a metrics server/scraper that scrapes the metrics off the collector, a time series database where the metrics are stored, a dashboard to display the metrics customized to the users needs, and finally a data processor to analyze the data which can then be fed to AI/ML tools for providing feedback to the lifecycle manager. In GIN, we are primarily using the TICK (Telegraf, InfluxDB, Chronograf, and Kapacitor) stack for analytics. However, based on our model driven approach we can easily support variations of the analytics stack that allows one to substitute the elements of the stack with components from other popular frameworks like Prometheus and Grafana.
The diagram below shows how the analytics stack fits in a closed loop automation of the common life cycle architecture. The analytics data processor sends data to an AI (artificial intelligence)/ ML (machine learning) tool, which along with policy engine and other applications provides a feedback to the life cycle manager to alter the operation of a service in an automatic way.
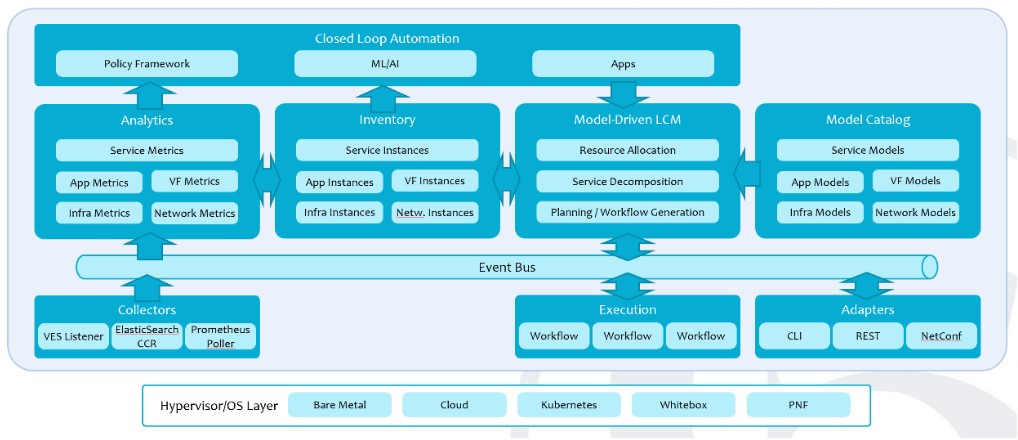
C. Catalogs – a persistent store for service models and associated artifacts. Since TOSCA enables us to define models as well as resources in a standard way, GIN has leveraged that to create a model catalog database whose schema is defined in terms of the TOSCA entities. This provides a
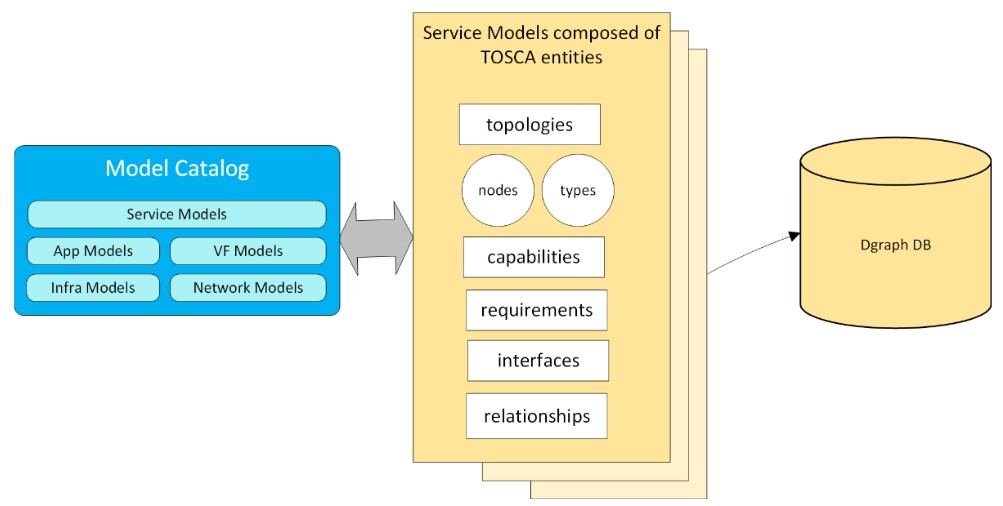
big advantage of saving all kinds of models and resources without having to change the schema. It overcomes a big deficiency of ONAP, where AAI schema has to be changed frequently to accommodate new resources that do not fit the current schema. CCI has chosen Dgraph as the graph database of its choice. It is a distributed graph database with a query language that is closely patterned after the standard GraphQL. The service model catalog includes models for services, virtual functions, resources, networks, infrastructure, analytics, policies, etc.
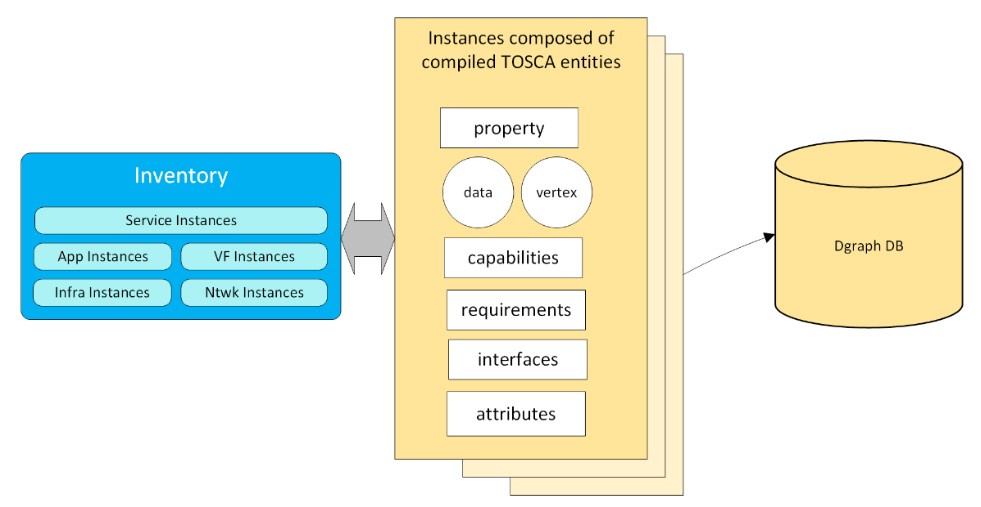
D. Inventory – a persistent store of service instances created by the Lifecycle Management Fabric. Like the service catalog, the inventory schema is also based on the tosca entities which makes it immune to changes in the types of services and resources. It is designed to handle all layers of the service stack (including service, app, VNFs, network, and available clouds instances).
E. Why TOSCA – to fully take advantage of model-driven management functionality, vendors, service designers, and operators must use a common modeling technology to ensure compatible representations of components, services, and runtime management functionality. There are a number of such modeling technologies that are used in the telecom industry. For example, YANG is a data modeling language that is the de-facto standard in the networking industry for defining schemas for network configuration data and runtime state. Most networking vendors provide YANG modules for configuring their equipment, and many internet RFCs have been created that standardize configuration data schemas that can be adopted by multiple vendors. While YANG was designed to model configuration data, some standards bodies have also used YANG for modeling end-to-end services. Those standards use YANG to define the components of which a service is composed as well as the configuration data and runtime state for each of those components.
Unfortunately, given that YANG is strictly a data modeling language, YANG cannot be used to express service-related semantics. For example, YANG does not allow you to specify which parts of the model define service components and which parts define configuration data for those components. That information can only be found in the standards documents that define the services in the first place. Similarly, the YANG language alone can also not be used to define dependencies between service components, or to express how some components can be decomposed using entire other service models. The YANG language does not have support for expressing those semantics in a general-purpose fashion.
Of course, service semantics are a must-have for service lifecycle management. Automated service lifecycle management systems must know which components make up a service, how those components depend on one-another, how instantiation and activation of those components must be sequenced, how configuration information may need to be propagated between components, etc. To avoid having to build service semantics for each service into the lifecycle management system, it must be possible to express service semantics using the service modeling language.
The industry standard for modeling services and automating service lifecycle management functionality is the Topology and Orchestration Specification for Cloud Applications (TOSCA). TOSCA is a domain-specific language standardized by OASIS for describing service topologies and their associated service lifecycle management operations. TOSCA’s focus is the definition of service semantics, which makes it unique in the following ways:
- Whereas YANG documents are trees, TOSCA uses graphs to model services. TOSCA service topology graphs explicitly model service components (using TOSCA nodes) and the dependencies between these components (using TOSCA relationships).
- For each component, TOSCA allows component designers to define the ports through which their components interact. TOSCA introduces capabilities and requirements for this purpose. Capabilities and requirements allow for modular design of reusable components, and they are an absolute requirement for model-driven service integration platforms.
- TOSCA includes data types for defining the schemas of configuration data for nodes and relationships. As such, TOSCA data type definitions are similar to YANG schema definitions. Unlike YANG, TOSCA also supports node and relationship types, capability types, interface types, and policy and workflow definitions. All of those are required for defining service management semantics.
- TOSCA allows individual components to be modeled using their own service sub topologies. This is useful to model how network functions can be disaggregated into collections of finer grain components.
Using TOSCA, it is possible to build general-purpose service lifecycle management systems that rely strictly on the semantics built into the TOSCA language without having to introduce service-specific knowledge into the management system.
Network Integration Fabric
Genie in a Network (GIN)™ Network Integration Fabric consolidated a lot of the network orchestration specification and logic into the life cycle manager. Therefore, what is left in the network integration fabric is a very thin layer consisting of a set of southbound adapters and northbound collectors.
- Southbound Adapters – provide the connection to send data to the network elements in a request/response pattern. Towards the framework they provide a RESTful interface for direct invocation when the connection manager in the integration fabric is known by the consumer. When the consumer does not know which instance is currently managing the connection, the event/communications services can be used, and the managing instance will respond to the request.
- Northbound Adapter – provide the ability to receive or collect data from the network. The generalized model is to use a subscribe/notify pattern as described in clause 3.8 of ETSI NFV-SOL015. However, other adapters may also be utilized. Data received/collected from the network is published on the events/communications services based on predefined data set names registered with the data registration and discovery services.
Management Integration Fabric
Genie in a Network (GIN)™ Management Integration Fabric consists mostly of components that makes the platform cloud native and provides a supporting foundation upon which other custom network management components can be deployed. The other layers in the platform also depend on the management fabric for common functionality concerning security, logging, tracing, etc.
- Service Registration/Discovery – management services may be connected by exposed service APIs. These can be by the service itself or through an API gateway. The service URLs are registered in the service catalog such that dependent services can discover them by querying the catalog.
GIN is a cloud native platform that supports the basic principles of a SOA with the implementations of a service domain provided by a related set of microservices. GIN shields the complexity of discovering, registering, managing, and routing service API calls behind an API gateway. GIN employs Apache APISIX as an API Gateway for its platform. It is an opensource cloud native API gateway based on NGINX and Etcd and comes with a GUI dashboard. The cloud native nature of the platform components and the applications, automatically makes available all the resources and capabilities of such an environment. It includes key infrastructure features such as scaling up/down individual components based on usage for more efficient use of infrastructure, load balancing and resiliency of components, configuration and state data storage, portability across heterogeneous environments, etc.
GIN uses an open-source tool called Argo CD to continuously deliver platform and application components. Argo CD is implemented as a Kubernetes controller which continuously monitors running applications and compares the current, live state against the desired target state (as specified in the Git repo)
- Data Registration/Discovery – management services may be connected by the data they publish or consume. Data publications should be registered such that subscribers can find the service endpoint for the data and access the data. The exposure has a publication and subscription class which can be filesystem (Fileserver URL), DBaaS (DB server URL), or Communications (Topic URL).
The GIN platform allows TOSCA models to define data topologies which provides a myriad of options to specify how the data flows from data producers to the data consumers, and how to send the data on its way through a data collection infrastructure onto a data event bus. The etcd catalog in the platform can be used to define metadata for the various data sources, connection data, endpoints, including the schema definitions.
The data topologies can be defined to process different kinds of data volumes. It can utilize tools appropriate for the data volumes it needs to handle. For large data volumes it can employ Big Data tools to process, transfer, and store the data.
- DBaaS/Data Persistence – the platform follows a Data Centric model where data can be stored and accessed without the need of intermediary services. The platform provides data persistence with potentially different files system types and DBaaS which can be one of several different Database types. These services may be multiple services for the type of data structure they support (LFS, HFS, Mongo, Postgres, MariaDB, etc.). Management services might have their own inventory services for objects they manage which can be implemented using the DBaaS and Data Persistence services in the Management Integration Fabric.
- Events/Communications – enabled through a bus which decouples the publishers from the consumers. Consumers can use either a pull or push model. The push model allows true event-based processing eliminating the need of resources for polling patterns. The service allows for dynamic topic creation, topic authorizations, and publish and subscribe procedures.
GIN has incorporated a NATS Jetstream distributed event bus into the platform. NATS JetStream is a distributed streaming system capable of capturing streams of events from distributed systems and microservices, IoT sensors, edge devices and software applications, and save them into persistent stores. It is built on a highly performant, resilient, secure, available, and easy to use NATS messaging system. With NATS JetStream, event streams are published by producers and replays of the streams from persistent stores are delivered to consumers.
Alternatively, GIN can also work with DMAAP event bus used in ONAP. GIN includes a Telegraph plugin for the VES collector which along with DMAAP can be used in the TICK (Telegraf, InfluxDb, Chronograf, and Kapacitor) stack for data analysis.
- Logging – this service allows logging to be abstracted from the services. The location and format of the log files need not be known by the log writer. However, for traceability, the logging record needs to be consistently filled in by all services such that troubleshooting can be performed when problems are discovered. GIN has adopted the opensource OpenTelemetry framework to generate and collect data consisting of metrics, traces, and logs to monitor and analyze the performance of the platform.
- Security – GIN leverages Istio service mesh security to secure services in a heterogenous environment. GIN has adopted Istio mesh security because it supports the SPIFFE (Secure Production Identity Framework for Everyone) specification. SPIFFE is a framework that allows one to bootstrap and issue identity to services distributed throughout heterogeneous environments and organizational boundaries. It has simple APIs that allow one to define short lived cryptographic identity documents—called SVIDs. When workloads need to authenticate to other workloads, they can use SVIDs to establish a TLS connection.
Istio provides a comprehensive security solution, including authentication, authorization, and auditing. It provides traffic encryption to defend against man-in-the-middle attacks, mutual TLS and fine-grained access policies to support flexible service access control, and auditing tools to provide an audit trail for tracking/trouble shooting purposes.
GIN uses a cloud native tool called cert-manager to add certificates and certificate issuers as resource types in Kubernetes clusters. It automates the provisioning of certificates within Kubernetes clusters. It provides a set of custom resources to issue certificates and attach them to services. It will ensure certificates are valid and up to date and attempt to renew certificates at a configured time before expiry. It can issue certificates from a variety of supported sources, including Let’s Encrypt, HashiCorp Vault, Venafi, and private PKI. - User Interface – almost all management systems need to expose functions and data to operations and administrative personnel. Therefore, a minimal portal interface leveraging the IDAM and API GW will be provided such that applications providing HTML5 content can be displayed in a browser.
Execution Fabric
A. Workflow
The execution fabric mainly consists of a workflow engine that executes the workflow steps generated by the life cycle manager from a service model. The workflow engine is a simple engine that executes the workflow steps in the correct order. It is triggered off events published to the messaging bus.
GIN has also incorporated an opensource cloud native workflow engine called Argo to execute the workflow steps in a container. Although we believe, for most instances the Argo workflow or the simple workflow engine will suffice, we can also plugin the open source Camunda workflow engine if a more robust and distributed workflow engine is preferred. In all cases the workflows will be automatically generated from the model.
B. Policy
The policy engine is a simple engine that executes the policy defined in a tosca model. It is also triggered off events published to the messaging bus. The GIN allows models to be built where the policies defined in the model can be translated to the policies which can be run by the Drools policy engine that comes with ONAP. In addition, GIN can also leverage the Kapacitor processor in the TICK stack to handle policies defined in terms of its alerts and handlers.
C. Analytics
The platform has adopted the TICK (Telegraf, InfluxDb, Chronograf, Kapacitor) stack – a collection of open source components that combine to deliver a platform for easily storing, visualizing and monitoring time series data such as metrics and events. The platform is flexible in allowing the models to plug in other opensource analytics components like Prometheus and Grafana to be substituted in place of some of the original TICK components.
Quality Assurance & Testing
Genie in a Network (GIN)™ platform relies on automation to ensure that every release cycle is accompanied by a comprehensive level of regression testing to ensure system stability. The automation is built on utilizing Jenkins for CI/CD and Robot framework for acceptance testing. One of the key benefits of automation is immediate feedback which helps resolve issues quickly during the development process. The unit tests built during the development phase help test the code functionality at a very granular level, and maintain a minimum level of test code coverage.
Use Cases
Genie in a Network (GIN)™ platform comes with a number of use cases implemented to demo how to deploy various network functions/services.
A. ORAN Service Model – demonstrates TOSCA based O-RAN deployments, focusing on the following:
- Cloud infrastructure deployments, including at the Edge
- Deployment of all O-RAN components, including SMO & RICs. CU, DU, and RU have not been implemented due to incomplete open source solutions at the present. The model will be enhanced as O-RAN-SC introduces support for those components.
- Deployments for traffic steering consisting of QP (QoE Predicter), QP-driver (helper function between TS and QP), and TS (Traffic Steering) xApps
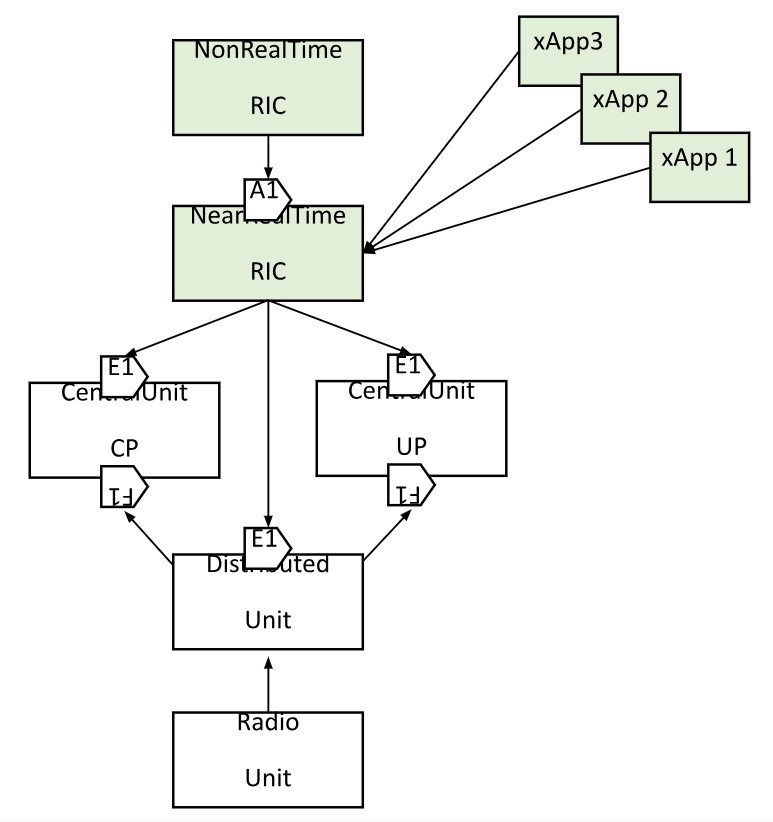
The use case consists of 5 TOSCA models one each for non-real time RIC, near-real time RIC, and each of the xApps. The non-realtime and near-real time RIC components are deployed as Kubernetes pods using Helm charts packaged as artifacts in their respective TOSCA model archives (.CSAR files). The xApp TOSCA models have support for xApp onboarding and deployment.
B. SD-WAN Service Model – software-defined wide-area network is a specific application of software-defined networking (SDN) technology applied to WAN connections such as broadband internet, 4G, LTE, or MPLS. It connects enterprise networks — including branch offices and data centers — over large geographic distances.
GIN has an SD-WAN use case modelled in TOSCA to demonstrate one of the key aspects of SDWAN which is secured tunneling of data between two sites. This is achieved using open source SDWAN software from flexiWAN. The actual orchestration of the SDWAN components is done by the GIN life cycle manager.
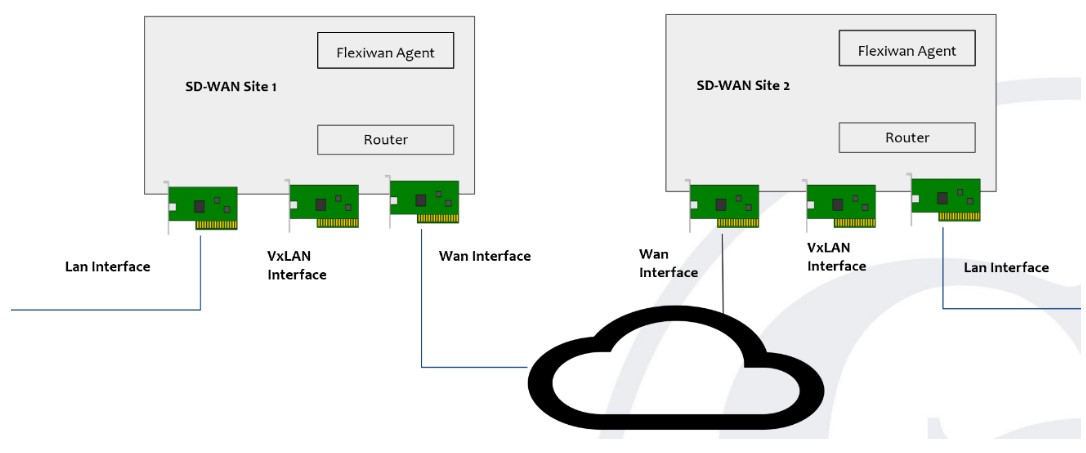
The objective of the use case is to demonstrate how GIN can perform lifecycle management of SD-WAN service without using the SD-WAN controller. Following steps were undertaken for the proof-of-concept solution:
- Deploy 2 SD-WAN devices in form of Linux virtual machines running on separate networks
- Install Flexiwan software on each device
- Start SD-WAN router service on each device
- Create secure tunnel endpoints
- Test branch connectivity between the end-points.
Steps#3 – #5 are done without engaging the Flexiwan controller. Instead, they are achieved through artifacts that are packaged with the TOSCA model.
C. Firewall Service Model – adopted from ONAP. It is composed of three virtual functions (VFs): packet generator, firewall, and traffic sink. These VFs run in three separate VMs. The packet generator sends packets to the packet sink through the firewall. The firewall reports the volume of traffic passing though to a collector. The packet generator includes a script that periodically generates different volumes of traffic. The closed-loop policy has been configured to re-adjust the traffic volume when high-water or low-water marks are crossed.
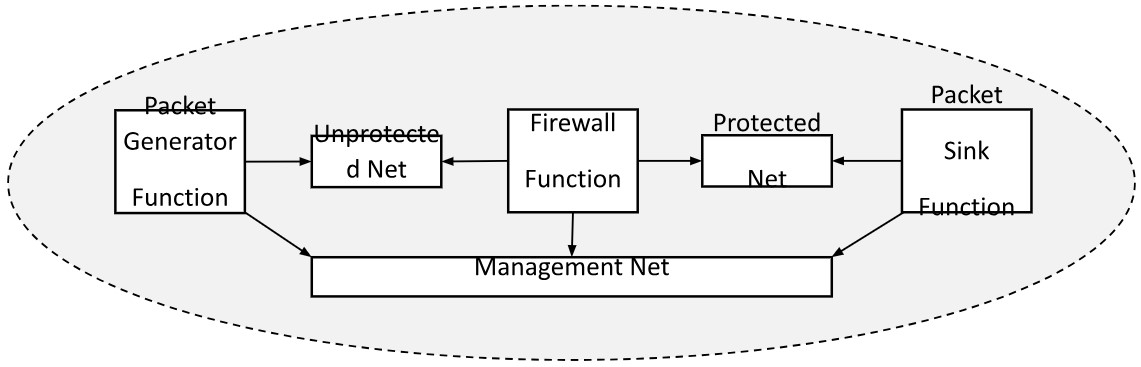
In ONAP the firewall is not based on a pure TOSCA model. Instead, it consists of heat templates packaged in a TOSCA .CSAR file. For GIN, the use case was designed from grounds-up to be completely specified using TOSCA spec 1.3. The use case demonstrates how you can deploy a firewall service using a pure TOSCA model that supports inferred workflow generation, policy definition in the model, a multi-cloud deployment using TOSCA substitution mapping, network set up, and infrastructure set up.
Management Services
Genie in a Network (GIN)™ have some basic set of management applications. The platform provides data collection and exposure for the following basic set:
A. Fault Management – tools continuously scan a network for problems, then analyze the situation and provide users with the solution they need to implement. Depending on the issue, the fault management tool may automatically dispatch restorative scripts or programs to instantly fix problems. Fault management is important in both finding and fixing network problems, and is an invaluable resource for network teams.
Fault management operates on a continuous cycle that always looks for problems on your network. While every fault management program’s specific process is different, the general fault management cycle follows the same basic steps:
- Detection. The fault management tool checks the network and discovers problems that affect performance or data transmission.
- Diagnosis. The tool determines what the problem actually is and where on the network it’s located.
- Alerting. The tool alerts the user to the problem. If a tool creates multiple alerts about the same problem, it automatically correlates them and combines them into one alert before sending it.
- Resolving. The tool automatically executes programs or scripts designed to fix the problem. If the automatic solutions don’t work, the management program recommends manual intervention.
B. Configuration Management – service for switches, routers, firewalls and other network devices helps automate and take total control of the entire life cycle of device configuration management. Some of the key features it provides are as follows:
- Real time change management – Monitor configuration changes, get instant notifications and prevent unauthorized changes to make your networking environment secure, stable and compliant.
- Compliance auditing – Define standard practices and policies, check device configurations for violations and readily apply remedial measures to ensure device compliance.
- Automatic configuration tasks – Save time by automating repetitive, time-consuming configuration management tasks and also by centrally applying configuration changes to devices in bulk.
- User activity tracking – Improve accountability and get a complete record of the who, what and when of configuration changes.
C. Performance Management – collective techniques that enable, manage and ensure optimal performance levels of a computer network. It generally requires the performance and quality service level of each network device and component to be routinely monitored.
At a minimum, business continuity demands seamless network availability and application performance. The performance manager’s service assurance will help validate performance expectations for the network while quickly pinpointing trouble spots to minimize disruptions and help users do their jobs. Network performance management helps, hopefully in a pre-emptive manner, unearth network issues that could hamper the optimal operation such as:
- Network delays
- Packet losses
- Throughput
- Packet transmission
- Error rate
The basic set of network management services can be a starting point for operators, and can easily be extended by either CCI as a product or service, by the operator themselves, or by a 3rd party, because it is built on an open architecture.
Service Orchestrator
CCI's Genie in a Network (GIN)™ service orchestrator is one of the key components of its comprehensive next-generation GIN network lifecycle platform.
The GIN service orchestrator is a TOSCA-based service orchestrator that addresses the challenges of handling increased need for automation, being cloud native, and dealing with infrastructure on which it runs. It can handle a comprehensive model of a service including resources, workflows, policies, and analytics it depends on – all defined in one location. The GIN orchestrator supports the basic principles of a SOA with the implementations of a service domain provided by a related set of microservices. The GIN Orchestrator comes with a rich set of APIs that allow it to be independently integrated into other management platforms. GIN shields the complexity of discovering, registering, managing, and routing its API calls behind an API gateway. It employs Apache APISIX as an API Gateway for its platform. It is an opensource cloud native API gateway based on NGINX and etcd and comes with a GUI dashboard. The cloud native nature of the orchestration solution automatically makes available all the resources and capabilities of such an environment. It includes key infrastructure features such as scaling up/down individual components based on usage for more efficient use of infrastructure, load balancing and resiliency of components, configuration and state data storage, portability across heterogeneous environments, etc.
It adopts a number of core foundational principles to tackle the complexity of modern network deployments:
Declarative – A declarative approach reduces complexity. It focuses on the “what” rather than the “how”. The automation platform translates the declarative to the imperative.
Model-Driven – A model-driven approach provides a consistent set of models used by all platform components. It helps automation by using the meta-model or “modeling language” to define the automation functionality associated with the modeled components.
End-to-End – Service designers and network function designers can design all aspects of the service in one place. Service and network function deployment packages support all aspects of Day 0 design, and Day 1 deployment, including service assurance.
Comprehensive - End-to-end automation systems must not only handle lifecycles and assurance of services and network functions, but also the infrastructure on which network functions are hosted.
Cloud-Native – A cloud-native system helps facilitate a loosely-coupled event-driven architecture over tightly-coupled monolithic systems. It allows us to dynamically scale network management functions and make them easily distributable all the way to the edge.
Open and Extensible – The architecture supports open interfaces (APIs) to integrate with existing management systems and to support addition of custom management functionality.
These foundational principles allow true automation without adding complexity.
The key features of the platform can be summarized as follows:
- Consistent TOSCA based models for Day 1 orchestration and Day 2 operation, removing the need for subdomain orchestrators like APPC, VNFC, and SDNC.
- Inferred workflows from relationships defined in the service model
- Explicit workflows can also be specified in the TOSCA model. No separate definition required in an external workflow engine.
- Policies can be specified in the TOSCA model. No separate definition required in an external policy framework/engine.
- Monitoring and analytics designed in conjunction with services and service components, and bundled with Service Models.
- Multi-cloud deployment for a model can be declared in the model using the TOSCA substitution mapping feature
- Persistence storage for the model and resources built on TOSCA entities, that requires no changes to the schema for new resources or components.
While GIN is inspired by ONAP, GIN adopts a fundamentally different architecture which allows it to address the many shortcomings of ONAP as will be highlighted in this document. The main areas of the architecture of GIN are presented in detail in the remaining sections of this document.
TOSCA Based Orchestrator
The Model-Driven Lifecycle Manager replaces the Service Orchestrator as well as the controllers in ONAP with pure TOSCA-based orchestrator. The TOSCA meta-model defines abstractions that are fully aligned with its mission as service orchestration language. It introduces service topologies as first-class abstractions, which are modeled as graphs that contain the components (“nodes”) that make up a service as well as the relationships between these components. Each component can in turn be modeled as a (sub) topology of more fine-grain nodes and relationships. The decomposition is recursive, which allows for fine-grain components. TOSCA types allow for the creation of reusable components, TOSCA requirements allow service designers to express resource requirements directly in their service models to be matched at orchestration time with capabilities of inventory resources and modeled using the same TOSCA meta model. The supported lifecycle management operations are defined on each node using Interfaces and Operations and implemented using Artifacts. TOSCA’s service-focused meta model enables automated general-purpose orchestration capabilities.
The lifecycle management functionality of controllers/sub-domain orchestrators is built around the same service-focused meta model as the master orchestrator. This allows us to turn controllers into domain-specific orchestrators, built using the same orchestration functionality as the master orchestrator, but using domain-specific TOSCA models. The communication between master orchestrator and controllers follows a “decompose and delegate” paradigm. Controllers can further decompose components internally using TOSCA substitution mapping, avoiding the need for monolithic plug-ins. As a result, the “domain level orchestrators” (controllers) in ONAP such as, APPC, VNFC, and SDNC have been eliminated.
Most service orchestration workflows have complex dependencies which results in complex sequencing of orchestration steps. The sequencing may be too complicated for humans to get right, orchestration software is better equipped to determine sequencing of orchestration steps based on dependencies represented in service topology. We can bundle service-specific orchestration logic together with service models in a way that can be understood by all orchestrator components. We can also bundle service-specific policies together with service models, all defined using the same TOSCA language.
Since TOSCA specification's support for workflows and policies is more than adequate for what is needed, we significantly reduce the complexity of the current ONAP implementation which depends on tediously convoluted and full-blown workflow engines like Camunda, and Drools based policy engines to fulfill this requirement.
TOSCA enables us to define all service specifics in one place, that can be understood by the orchestrator in a service-independent way.
The TOSCA based orchestrator is implemented using a Golang based microservice and has a REST API for integration with external applications.
TOSCA Model Registry
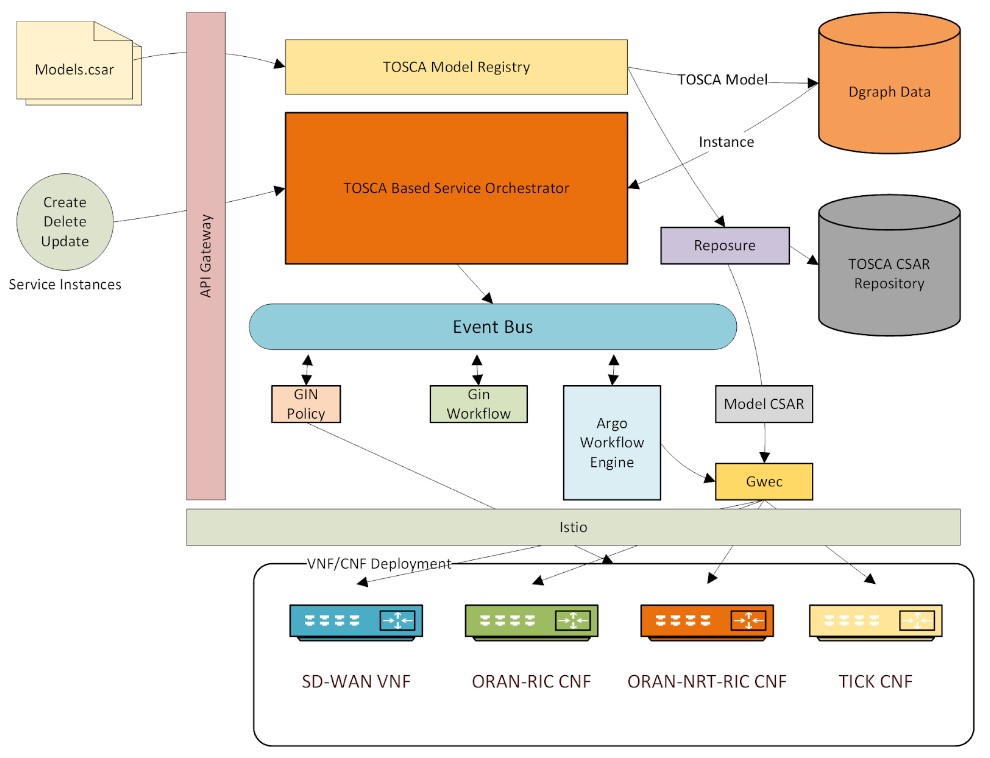
The orchestrator is accompanied with a model registry that compiles and saves the TOSCA based models into a service catalog database. It also saves the TOSCA model archive that include its aritifacts into a repository in the cloud. This makes the contents of the model .CSAR archives available to the orchestrator during execution of the model workflow. The Model Registry component uses the Reposure microservice to save the model archive (.CSAR) file into the model repository.
- Reposure - microservice is responsible for managing and accessing cloud-native container image registries for Kubernetes. The GIN orchestrator uses it to save the model TOSCA archives (.CSAR) and make it available to the workflow engine anywhere across the cloud.
TOSCA Model Database
The TOSCA meta-model defines abstractions that are fully aligned with its mission to define models as well as resources in a standard way, GIN has leveraged this fact to create a model catalog database whose schema is defined in terms of the TOSCA entities. This provides a big advantage of saving all kinds of models and resources without having to change the schema. It overcomes a big deficiency of ONAP, where AAI schema has to be changed frequently to accommodate new resources that do not fit the current schema. CCI has chosen Dgraph as the graph database of its choice. It is a distributed graph database with a query language that is closely patterned after the standard GraphQL. The service model catalog includes models for services, virtual functions, resources, networks, infrastructure, analytics, policies, etc.
Event Bus
Communications are enabled through a bus which decouples the publishers from the consumers. Consumers can use either a pull or push model. The push model allows true event-based processing eliminating the need of resources for polling patterns. The service allows for dynamic topic creation, topic authorizations, and publish and subscribe procedures.
GIN has incorporated a NATS Jetstream distributed event bus into the platform. NATS JetStream is a distributed streaming system capable of capturing streams of events from distributed systems and microservices, IoT sensors, edge devices and software applications, and save them into persistent stores. It is built on a highly performant, resilient, secure, available, and easy to use NATS messaging system. With NATS JetStream, event streams are published by producers and replays of the streams from persistent stores are delivered to consumers.
Alternatively, GIN can also work with DMAAP event bus used in ONAP. GIN includes a Telegraph plugin for the VES collector which along with DMAAP can be used in the TICK (Telegraf, InfluxDb, Chronograf, and Kapacitor) stack for data analysis.
Workflow Engine
The GIN workflow engine generates and executes the workflow steps generated by the orchestrator from a service model. The workflow engine is a simple engine that executes the workflow steps in the correct order. It is triggered from events published to the event bus.
GIN has also incorporated an opensource cloud native workflow engine called Argo to execute the workflow steps in a container. Although we believe, for most instances the Argo workflow or the simple workflow engine will suffice, we can also plugin the open source Camunda workflow engine if a more robust and distributed workflow engine is preferred. In all cases the workflow steps are either derived and generated from the model or explicitly specified in the model.
- GWAP – Gin Argo Workflow Plugin - microservice is responsible for generating the workflow template, which is compatible with the Argo workflow engine, from the model. It listens on the event bus for an event that acts as a signal for it to start generating the workflow. It fetches the service instance of a model from Dgraph database and generates the Argo workflow template which it subsequently submits to the Argo workflow engine. One of the key features of Argo Workflow Engine is that it executes each workflow step in a separate container. The workflow steps can therefore leverage the full scalability and reliability of the cloud infrastructure. It also allows the workflow steps to be executed in containers hosted within a single pod. This can be used to efficiently execute workflow steps that are closely knit together and share a lot of common resources between them.
- GWEC – Gin Workflow Execution Component - microservice is used to execute each workflow step in an Argo workflow template. It is a microservice with all the tooling necessary (e.g., an appropriate operating environment like Centos, Ubuntu, Windows, etc., Kubernetes deployers like Helm, scripting tools like Python and bash, etc.) to support the artifacts accompanying a TOSCA service model archive (.CSAR). The Argo workflow engine deploys the GWEC container for each workflow step, executes the step, and destroys the instance after completion of the workflow step.
- Argo Workflow Engine - works with the workflow template generated by the GWAP microservice and executes each workflow step in the GWEC container. It is setup to listen for workflow execution events on the event bus. On receiving the appropriate event it begins executing the workflow steps in a cloud native way. It publishes an appropriate event on the bus upon success or failure of the workflow execution. The subscribing components can react accordingly to the published event.
Policy Engine
The policy engine is a simple engine that executes the policy defined in a tosca model. It is also triggered off events published to the event bus. The GIN allows models to be built where the policies defined in the model can be translated to ones that can be processed and implemented by different policy engines. For example, even though GIN has its own policy engine component to handle simple policies, it can also leverage the Kapacitor processor in the TICK stack to handle policies defined in terms of its alerts and handlers. It also makes it easy to integrate policies that can be run by more elaborate policy engines like the Drools policy engine incorporated in ONAP.
Security
GIN leverages Istio service mesh security to secure services in a heterogenous environment. GIN has adopted Istio mesh security because it supports the SPIFFE (Secure Production Identity Framework for Everyone) specification. SPIFFE is a framework that allows one to bootstrap and issue identity to services distributed throughout heterogeneous environments and organizational boundaries. It has simple APIs that allow one to define short lived cryptographic identity documents—called SVIDs. When workloads need to authenticate to other workloads, they can use SVIDs to establish a TLS connection.
Istio provides a comprehensive security solution, including authentication, authorization, and auditing. It provides traffic encryption to defend against man-in-the-middle attacks, mutual TLS and fine-grained access policies to support flexible service access control, and auditing tools to provide an audit trail for tracking/trouble shooting purposes.
GIN uses a cloud native tool called cert-manager to add certificates and certificate issuers as resource types in Kubernetes clusters. It automates the provisioning of certificates within Kubernetes clusters. It provides a set of custom resources to issue certificates and attach them to services. It will ensure certificates are valid and up to date and attempt to renew certificates at a configured time before expiry. It can issue certificates from a variety of supported sources, including Let’s Encrypt, HashiCorp Vault, Venafi, and private PKI.
Service Orchestration Workflow
The platform comes with a number of use cases implemented to demo how to deploy various network functions/services.
The typical flow of steps for a service orchestrated by the GIN orchestrator are listed below:
Step1 : An external actor initiates an api call to the model registry microservice to register the dem model.
Step2: The model registry component compiles the TOSCA model.
Step3: The model registry component saves the TOSCA model in the Dgraph database.
Step4: The model registry component delegates to the Reposure component for saving the model archive (.CSAR) file in a repository.
Step5: The Reposure microservice saves the model archive in a repository in the cloud to make it readily available to other components of the orchestrator. Once a model is fully registered in the system, it is available for service instance creation.
Step6: An external actor initiates an api call to the TOSCA based service orchestrator to create a service instance from a model that has been previously registered in steps 1– 5.
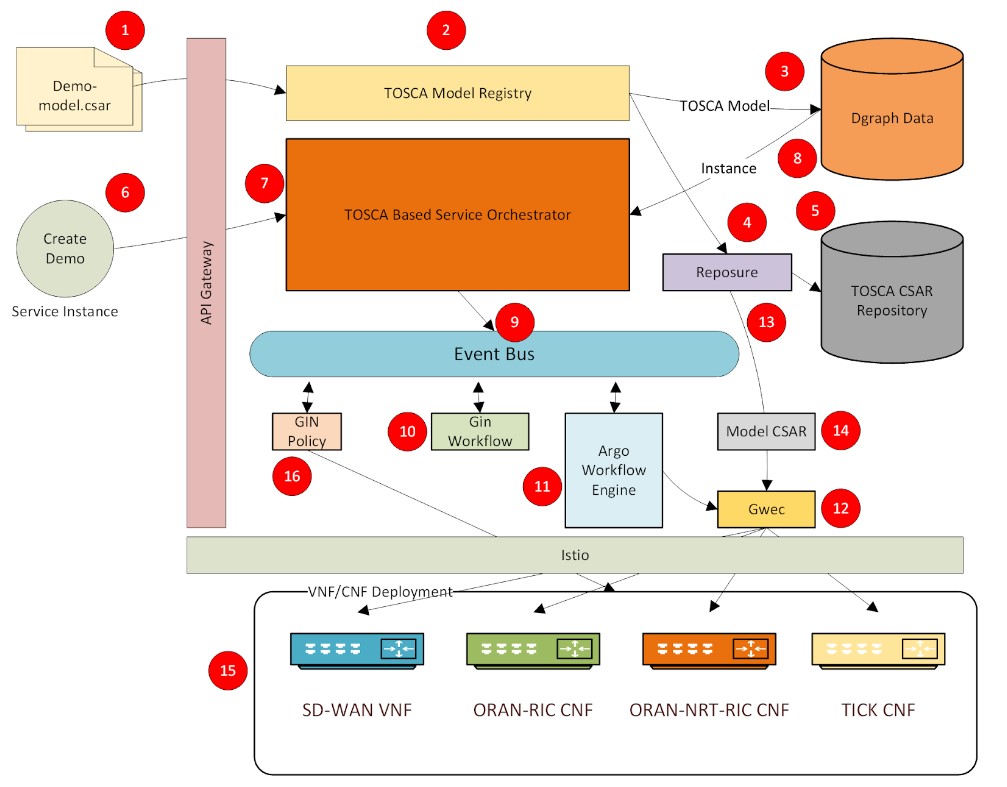
Step7: The service orchestrator reads the model from the Dgraph database and compiles it into a service instance resolving all the relationships and references defined in the model.
Step8: The service orchestrator saves the service instance in the Dgraph database.
Step9: The service orchestrator publishes an event to the bus indicating the service instance is ready for creation.
Step10: The GAWP microservice that is subscribing to the instance creation event generates the Argo workflow template from the relationships defined in the model and in turn publishes an event indicating that the workflow has been generated.
Step 11: The Argo workflow service subscribes to the workflow generation event, begins to process the workflow.
Step 12: The Argo workflow executes each step of the workflow in a GWEC microservice.
Step 13: The Reposure service fetches the requested model artifacts from the repository and delivers it to the GWEC component that is executing the workflow step.
Step 14: The GWEC component extracts the artifacts from the model returned by the Reposure service, and executes the next workflow step as dictated by the Argo workflow engine.
Step 15: The orchestrated service is deployed
Step 16: If there are any policies defined in the model, the orchestrator applies them to the deployed service. Any closed loop policies are set up at this stage of the orchestration.
A. ORAN Service Model - demonstrates TOSCA based O-RAN deployments, focusing on the following:
- Cloud infrastructure deployments, including at the Edge
- Deployment of all O-RAN components, including SMO & RICs. CU, DU, and RU have not been implemented due to incomplete open source solutions at the present. The model will be enhanced as O-RAN-SC introduces support for those components.
- Deployments for traffic steering consisting of QP (QoE Predicter), QP-driver (helper function between TS and QP), and TS (Traffic Steering) xApps
The use case consists of 5 TOSCA models one each for non-real time RIC, near-real time RIC, and each of the xApps. The non-realtime and near-real time RIC components are deployed as Kubernetes pods using Helm charts packaged as artifacts in their respective TOSCA model archives (.CSAR files). The xApp TOSCA models have support for xApp onboarding and deployment.
B. SD-WAN Service Model - software-defined wide-area network (SD-WAN or SDWAN) is a specific application of software-defined networking (SDN) technology applied to WAN connections such as broadband internet, 4G, LTE, or MPLS. It connects enterprise networks — including branch offices and data centers — over large geographic distances.
GIN has an SD-WAN use case modelled in TOSCA to demonstrate one of the key aspects of SDWAN which is secured tunneling of data between two sites. This is achieved using open source SDWAN software from flexiWAN. The actual orchestration of the SDWAN components is done by the GIN Orchestrator.
The objective of the use case is to demonstrate how GIN can perform lifecycle management of SD-WAN service without using the SD-WAN controller. Following steps were undertaken for the proof-of-concept solution:
- Deploy 2 SD-WAN devices in form of Linux virtual machines running on separate networks
- Install Flexiwan software on each device
- Start SD-WAN router service on each device
- Create secure tunnel endpoints
- Test branch connectivity between the end-points.
Steps#3 - #5 are done without engaging the Flexiwan controller. Instead, they are achieved through artifacts that are packaged with the TOSCA model.
C. TICK Based Service Model - demonstrates a service having a closed loop policy with a data collection and processing stack from Influx called TICK. It is composed of four services: metrics generator, VES Telegraf data collector, Influx time series database, Chronograf data visualizer, and Kapacitor data processor. These are all microservices deployed in a Kubernetes cluster. The metrics generator reports volume of traffic passing though to the VES Telegraf data collector which uses the DMAAP messaging bus. The metrics generator includes a REST API that allows the volume of traffic it generates to be changed. The VES Telegraf collector stores the metrics in Influx time series database. The Kapacitor data processor reads the data from the time series database, and generates events based on alarms setup to trigger when certain thresholds for the traffic volume are breached. These alarms are configured to send notification events to the DMAAP event bus where the GIN Policy engine is listening for such events to update the traffic volume on the metrics generator. The closed-loop policy has been configured to re-adjust the traffic volume when high-water or low-water marks are crossed.
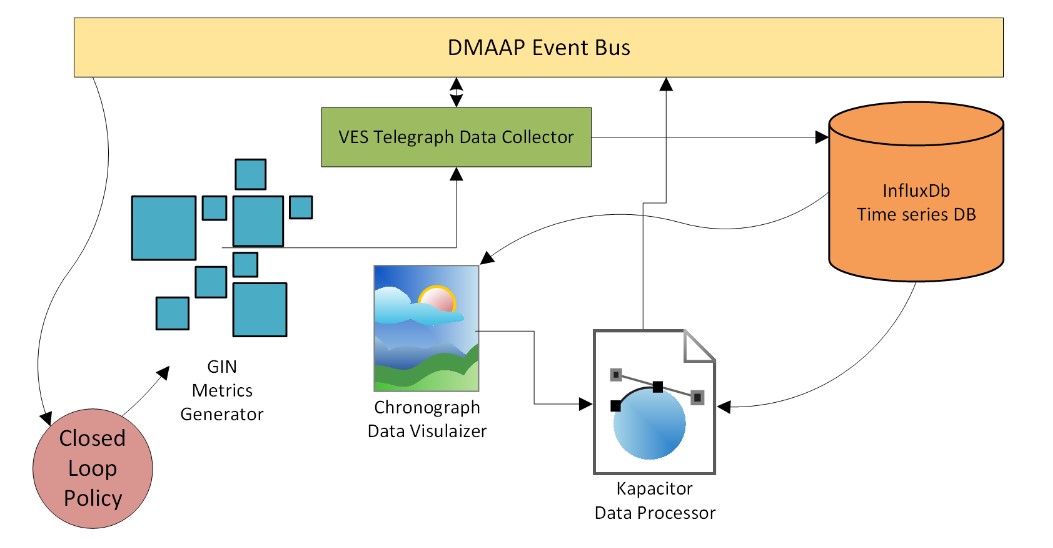
The Chronograf visualizer is used to display the metrics and show how the closed loop policy is working to keep the trafific volume flowing within a range between the low and high thresholds.
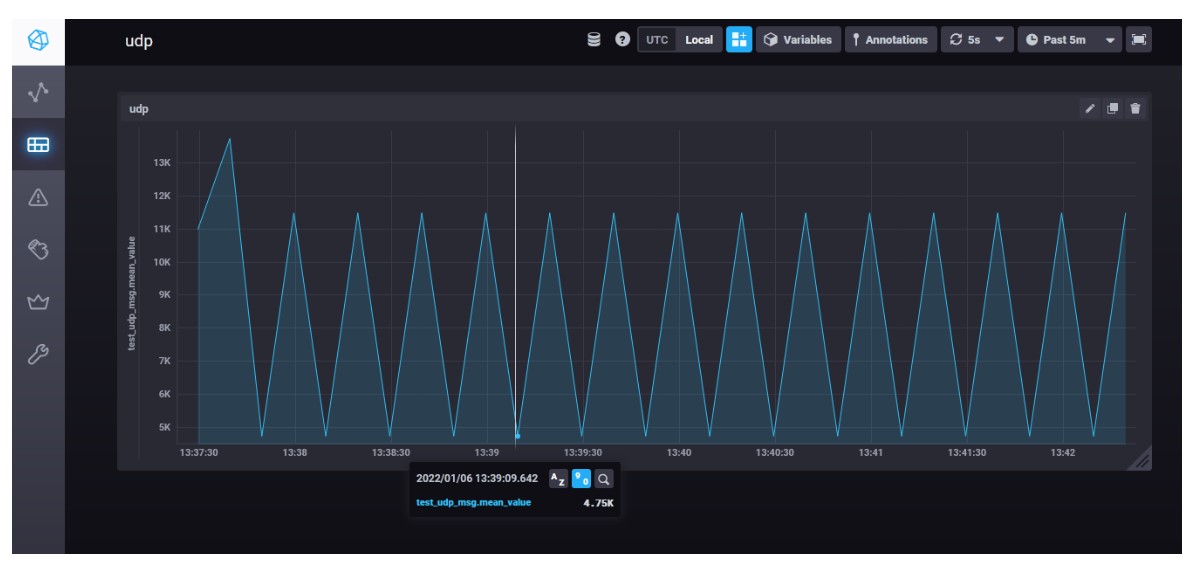
The low and high traffic alerts are setup as shown below in the Komparator to post events to the messaging bus.
The graph below shows the workflow steps executed to deploy/orchestrate this use case.
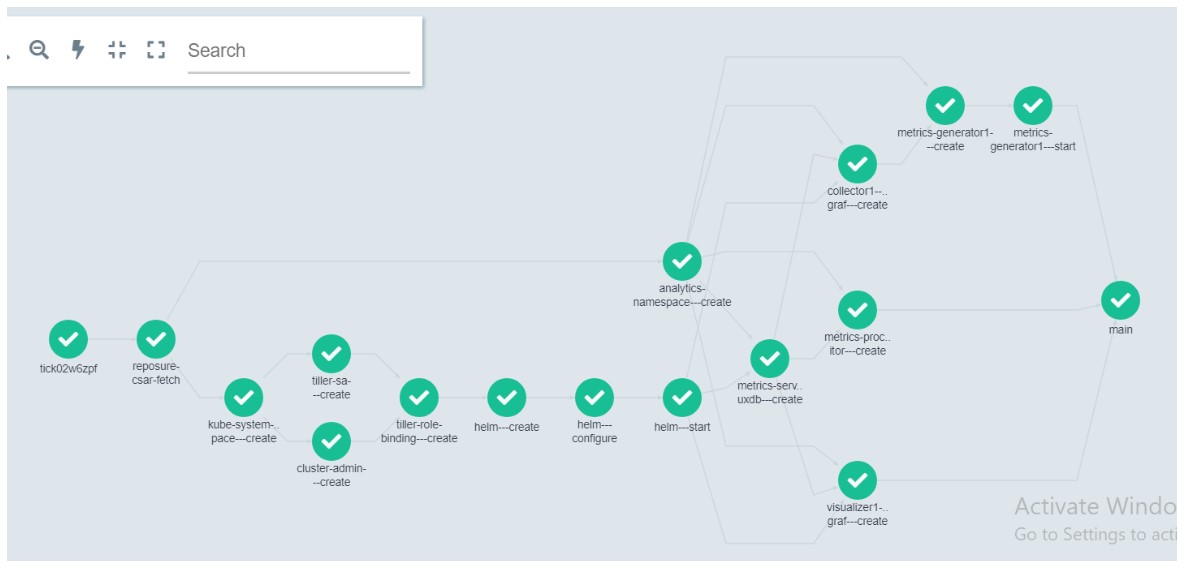
The TICK use case deployment starts with fetching its archive (.CSAR file) from the repository.
It then creates k8s namespaces -- tick and kube-system. In kube-system namespace, k8s resources
like Helm, ClusterRole and ClusterRoleBinding are created. All TICK model specific deployment
happens in the tick namespace. Following this, the TICK services namely Telegraph, Kapacitor, Chronograf and Influxdb are deployed in the kubernetes cluster. Finally, the GIN metrics generator service is deployed which sends metrics traffic to the VES collector at a rate determined by number of streams specified.
Here are the details of each step in workflow executed in GWEC (GIN workflow executer container):
- tick{INSTANCE_NAME} :
This is the initial step in Argo workflow for this deployment
- reposure-csar-fetch:
Fetches the TICK TOSCA model archive file CSAR from Reposure.
- kube-system-namespace---create:
Create 'kube-system' namespace in Kubernetes cluster if it does not already exist.
- tiller-sa---create:
Creates tiller (the server portion of Helm 2.0) if it does not already exist in the Kubernetes cluster.
- cluster-admin---create:
Creates Cluster Role in kubernetes, which is a set of permissions that can be assigned to resources within a given cluster.
- tiller-role-binding---create:
Creates ClusterRoleBinding in kubernetes. ClusterRoleBinding is used to grant permissions or access to the cluster.
- helm---create:
Gets the required files for installing helm.
- helm---configure:
Configures the helm service.
- helm---start:
Starts helm service.
- analytics-namespace---create:
Create tick namespace which gets used for deploying tick component services.
- metrics-server1---influxdb---create:
Deploy influxdb time-series database service in tick namespace.
- metrics-processor1---kapacitor---create:
Deploys kapacitor pod in tick namespace through helm chart. Kapacitor is used
for creating alerts.
- visualizer1---chronograf---create:
Deploys Chronograf pod in tick namespace through helm chart. Chronograf is GUI for kapacitor which is used to quickly see the data stored in InfluxDB.
- collector1---telegraf---create:
Deploys Telegraf pod in tick namespace through helm chart. Telegraf is a plugin-driven server agent for collecting and sending metrics and events from databases. telegraf sends data to gintelclient.
- metrics-generator1---create:
Creates gintelclient pod in tick namespace through helm chart. gintelclient is a used for sending packets to
kapacitor based on number of streams specified from telegraf.
- metrics-generator1---start:
Deploys gintelclient pod in tick namespace through helm chart
- main:
Main is final step which is used for just specifying end of workflow execution.
Based on the dependencies between the work flow steps, where appropriate, the steps are executed in parallel.